Desktop Live · 2026 Own product
AI Knowledge Hub.
I built Knowledge Hub for clients with sensitive documents who couldn't pipe them through OpenAI. RAG over your local files, streaming chat, an Ollama model manager — 100% on your machine. Now lives inside EnterpriseCore as a first-class module.
The problem.
Cloud-hosted RAG is a privacy and lock-in problem for any business handling internal documents, client work, or regulated data. Off-the-shelf "chat with your docs" tools push everything to a vendor's servers. I wanted the same UX, but with zero data egress.
What I built.
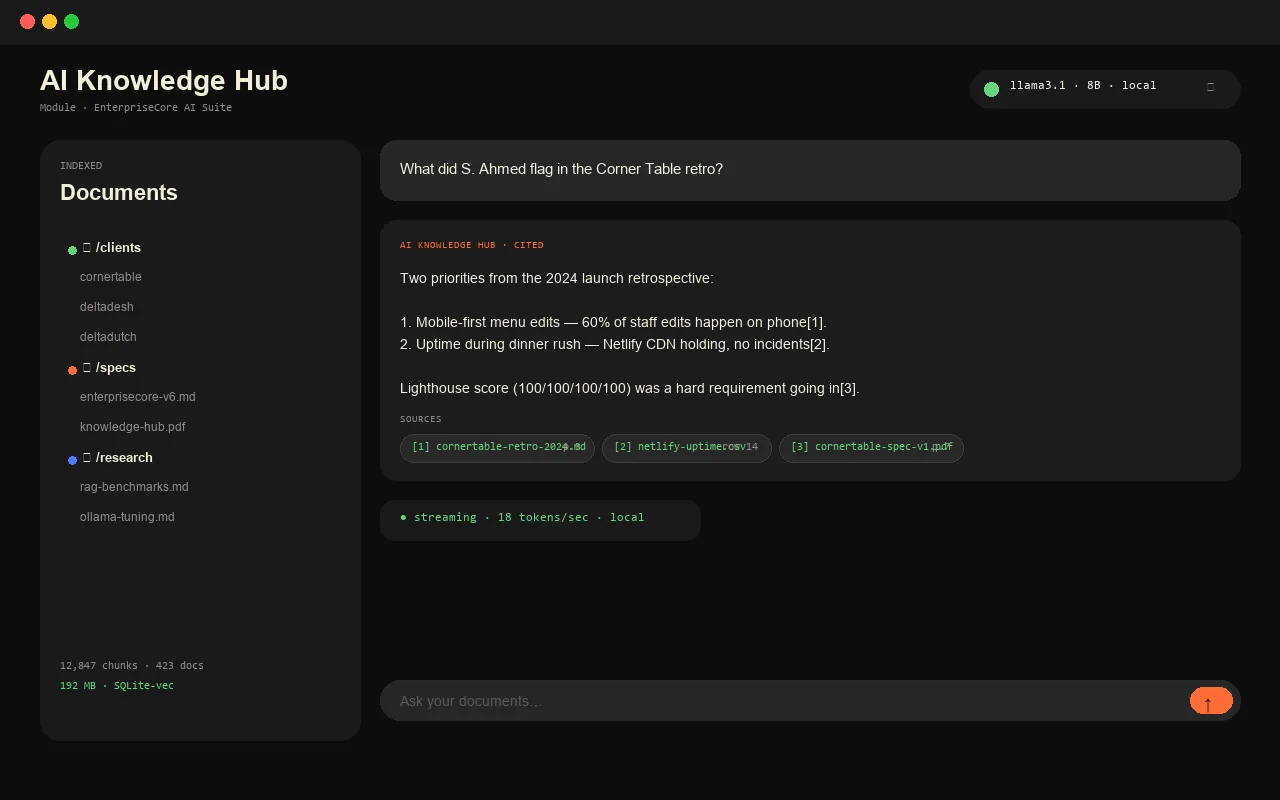
- Drop-a-folder ingestion. Point it at a directory of PDFs, markdown, code, or office files. It chunks, embeds, and indexes locally.
- Streaming chat. Server-sent events from FastAPI → React. Feels as fast as Claude or ChatGPT, but the tokens come from your machine.
- Ollama model manager. Browse, pull, switch, and benchmark local models from the same UI. No CLI required.
- Citations. Every answer cites the file + chunk it came from. Click to jump to the source.
- Lives inside EnterpriseCore. Same Electron shell, same FastAPI process, same SQLite database — just another module.
How I shipped it.
- SQLite-vec for vectors. No external vector DB. The embeddings live in the same SQLite file as the rest of the app.
- Ollama via subprocess. Inference goes through Ollama's local HTTP server; the desktop app spawns and manages it.
- Streaming end-to-end. FastAPI streams tokens via SSE; React renders them as they arrive.
- Citations as a primary feature. The retrieval layer threads source metadata through to the response — not bolted on.
Chat with your docs. Your docs never leave.
— the entire pitch in eight words
Like what you read? I can ship this for you.
Send a one-line scope and I'll quote within 24h. Three engagement shapes — fixed-price MVP, embeddable widget, or maintenance retainer.